

-
1 Inleiding
Q-methodologie ontstond in de psychologie, maar wordt tegenwoordig in vele disciplines toegepast (zoals ruimtelijke ordening, gezondheidszorg en bestuurskunde). De bedenker, William Stephenson (1935), wilde met zijn methode personen als een complex geheel bestuderen en niet hun kenmerken, zoals gangbaar is in statistische methoden. Hij ontwikkelde een manier om denkpatronen binnen een groep in kaart te brengen. Door systematisch te bestuderen hoe individuele visies verschillen, kan Q-methodologie significant verschillende discoursen – en welke aspecten van die discoursen verschillend of juist vergelijkbaar zijn – blootleggen.
Ook vanuit beleidsonderzoekers is er steeds meer interesse in Q-methodologie (Molenveld, 2017). Aan de ene kant wellicht door het besef dat beleidsprocessen steeds meer worden uitgevoerd tussen organisaties en actoren en dat hun perspectief op beleid het proces kan informeren, verbeteren en beïnvloeden (Teisman et al., 2009). Aan de andere kant beschrijft de literatuur over wicked beleidsproblemen dat sommige stakeholders over sommige onderwerpen significant van mening verschillen (Head & Alford, 2015). Q-methodologie is een methode die kan helpen om de grote vragen van beleidsmakers en -onderzoekers te beantwoorden, omdat het systematisch inzicht geeft in perspectieven en kan helpen om beleid te informeren, te beschrijven, maar ook te bekijken hoe beleid binnen een bepaalde groep wordt geëvalueerd.
In Nederland is het aantal Q-methodologietoepassingen schaars, en hetzelfde geldt voor het aantal Nederlandstalige teksten die inzicht geven in hoe de methode toegepast kan worden. Deze bijdrage belicht daarom de belangrijkste aspecten van de methode. Stapsgewijs bieden we in dit artikel inzicht in de belangrijke fasen van een Q-methodologische studie, ondersteund door illustraties vanuit een aantal Nederlandse en Vlaamse toepassingen. In de volgende paragrafen reiken we allereerst de belangrijkste theoretische en analytische bouwstenen aan. Vervolgens beschrijven we een 10-stappenplan om zelf aan de slag te gaan met de methode, om te eindigen met de voor- en nadelen van de methode en een afsluiting. -
2 De methode aan de hand van vijf bouwstenen
In dit artikel willen we een helder overzicht geven van wat Q-methodologie inhoudt en hoe je een Q-methodologische studie uitvoert. Daarvoor is het belangrijk om de ‘bouwstenen’ van Q-methodologie te kennen. In deze paragraaf introduceren we alle bouwstenen van de methode aan de hand van een aantal voorbeelden. Drie van deze voorbeeldstudies richten zich uitsluitend op perspectieven binnen een ambtelijke context, terwijl voorbeeldstudies A en E ook de private sector meegenomen hebben in het onderzoek (zie ook tabel 1).
De vijf voorbeeldstudies zijn:
Evaluatie DBRA: Tussentijdse Evaluatie Deltabeslissing Ruimtelijke Adaptatie (De Graaff et al., 2017);
Participatieve monitoring: een verkenning naar participatieve monitoring bij de waterschappen (Minkman et al., 2017);
Rijkstrainees: een onderzoek naar de gedragsprofielen van rijkstrainees (Van der Steen et al., 2018);
‘Images of Coordination’: een onderzoek naar horizontale beleidscoördinatie in Vlaanderen (Molenveld et al., 2020);
Publiek-private samenwerking: een internationale vergelijking van vormen van publiek-private samenwerking (Warsen et al., 2019).
Deze voorbeeldstudies worden gebruikt om de vijf methodologische bouwstenen te introduceren:
Een geschikte onderzoeksvraag
Q-methodologie is geschikt als men wil achterhalen welke perspectieven op het gekozen onderwerp er bestaan binnen een bepaalde groep.Een set stellingen (Q-set)
De zogeheten Q-set wordt opgesteld door het discours in kaart te brengen aan de hand van literatuur of een vooronderzoek.Deelnemers (P-set)
Een relatief klein aantal deelnemers (30 personen volstaat) wordt op zo’n manier geselecteerd dat alle mogelijke zienswijzen vertegenwoordigd zijn.Dataverzameling (Q-sorts)
Deelnemers sorteren de stellingen van meest eens naar minst mee eens.Analyse
De onderzoeker doet eerst een factoranalyse op basis van de correlaties tussen de Q-sorts en interpreteert deze factoren daarna (het maken van de zogeheten narratives).
Tabel 1 Overzicht van de vijf voorbeeldstudiesStudie Tussentijdse Evaluatie Deltabeslissing Ruimtelijke Adaptatie Participatieve monitoring waterschappen Gedragsprofielen van rijkstrainees ‘Images of Coordination’ Publiek-private samenwerking Focus van het onderzoek Evaluatie van de wijze waarop overheden, ondernemingen en organisaties worden gestimuleerd, gefaciliteerd en/of aangestuurd bij het ‘waterrobuust’ en klimaatbestendig inrichten van Nederland Verkenning van de acceptatie van participatief monitoren en welke rol is weggelegd voor participatief monitoren De rol van verschillende bestuurlijke waarden op het gedrag van ambtenaren Analyse van hoe medewerkers van uitvoeringsorganisaties horizontale beleidscoördinatie in Vlaanderen ervaren Vormen van publiek-private samenwerking, vergelijking tussen drie landen Type Evaluatie Input Beschrijvend Evaluatie Beschrijvend Deelnemers (P-set) 66 personen werkzaam voor een publieke of private organisatie (ondernemers, burgerinitiatieven, kennisinstellingen etc.) in vier representatieve gebieden waar gewerkt is aan ruimtelijke adaptatie 33 personen werkzaam bij 8 waterschappen in Nederland 116 young professionals werkzaam als rijkstrainee bij de Nederlandse rijksoverheid 29 Vlaamse ambtenaren uit 10 verschillende organisaties in 3 beleidsprogramma’s 119 mensen betrokken in PPS, waarvan 77 ambtenaren en 42 uit het bedrijfsleven; 44 van hen zijn Canadees, 40 Deens en 35 Nederlands Discours-analyse 50 interviews 10 interviews; 2 focus-groepen; literatuur Literatuur 25 interviews Literatuur Stellingen (Q-set) 25 46 32 45 24 Aantal kolommen -3 tot +3 (7) -4 tot +4 (9) -4 tot +4 (9) -5 tot +5 (11) -3 tot +3 (7) Sorteren In persoon In persoon Online In persoon Online Aantal perspectieven 3 3 4 3 4 Referentie (De Graaff et al., 2017) (Minkman et al., 2017) (Van der Steen et al., 2018) (Molenveld et al., 2020) (Warsen et al., 2019) Bouwsteen 1: onderzoeksvraag
Hoewel Q-methodologie vele toepassingsmogelijkheden kent, kan niet elke onderzoeksvraag met Q-methodologie beantwoord worden. Q-methodologie is geschikt om subjectiviteit systematisch te beschrijven. Subjectiviteit moet hierbij gelezen worden als de communicatie over iemands opvattingen met betrekking tot een bepaald onderwerp, bijvoorbeeld wanneer iemand zegt: ‘Naar mijn mening …’ (Mckeown & Thomas, 2011). Q-methodologie wordt gebruikt om systematisch patronen te achterhalen in deze individuele opmerkingen. Q-methodologie is bovendien van toegevoegde waarde in single case studies, omdat deze methode slechts een relatief klein aantal deelnemers vereist (meestal wordt een ondergrens van 30 gehanteerd) in tegenstelling tot andere (kwantitatieve) systematische studies (Brown, 1993). De methode beoogt zo te achterhalen welke perspectieven er bestaan binnen een bepaalde groep en wat deze kenmerkt; de vraag waarom een bepaalde subset van deze groep hetzelfde denkt, maakt geen deel uit van de analyse. De methode linkt dus geen respondenten aan een denkpatroon, maar zoekt binnen de gehele dataset naar significant verschillende denkpatronen. Q-methodologie beoogt om significante clusters van individuele ideeën met betrekking tot een probleem of een beleidsvraagstuk te achterhalen. Elk gevonden perspectief (cluster van ideeën) wordt door slechts enkele deelnemers volledig vertegenwoordigd en individuele kenmerken van respondenten (geslacht, leeftijd, opleidingsniveau, functieprofiel, et cetera) kunnen daardoor niet gerelateerd worden aan een specifiek perspectief. Op basis van een Q-methodologische studie kan men dus nooit een conclusie trekken in de trant van ‘de leeftijd van ambtenaren bepaalt hoe zij denken over onderwerp X’. De ‘waarom’-vraag (waarom een denkpatroon ontstaat of waarom een respondent deze mening heeft) kan het beste met alternatieve middelen worden bestudeerd, zoals interviews of focusgroepen (Molenveld & Nederhand, under review). De methode past dus het beste bij een explorerende of toetsende vraag rondom een single case.
Iemands subjectiviteit wordt bepaald door algemeen gedeelde denkbeelden in een groep, door (een van) de verschillende groepsperspectieven die daarbinnen bestaan, en door individuele opvattingen. Q-methodologie gaat ervan uit dat er een aantal gedeelde maar toch significant verschillende groepsperspectieven kunnen bestaan binnen zo’n groep (Kampen & Tamás, 2014). Q-methodologie is bedoeld om die verschillen bloot te leggen, oftewel om te onderzoeken welke significant verschillende zienswijzen er bestaan binnen een bepaalde groep (Brown, 1980). Q-methodologie wordt wel de brug genoemd tussen kwalitatief en kwantitatief onderzoek (Brown, 1996; Sell & Brown, 1984). Enerzijds verkrijg je als onderzoeker een goed beeld van de opvattingen van een persoon en een groep, via diepte-interviews, documentenstudies en dergelijke, en wordt het debat in een bepaalde groep kwalitatief gereconstrueerd, ex-ante dan wel ex-post. Anderzijds gebruikt Q-methodologie een kwantitatieve aanpak om de perspectieven te construeren en te vergelijken, namelijk door de dataset met de individuele subjectiviteit door middel van correlaties en een factoranalyse te clusteren en analyseren. Op deze manier benut Q-methodologie de voordelen van zowel kwantitatieve als kwalitatieve methoden.
De vraagstelling van de beleidsmaker of -onderzoeker moet natuurlijk bij deze methode passen. Onderzoeksvragen in Q-methodologie gaan over het in kaart brengen van groepsperspectieven. Zo stellen Warsen et al. (2019) de vraag: Hoe zien professionals in publiek-private samenwerkingsverbanden in Canada, Nederland en Denemarken de ideale bestuursrelatie in deze samenwerkingsverbanden? De perspectieven die binnen een groep bestaan, kunnen ook gebruikt worden als verklaring voor bijvoorbeeld procesuitkomsten of verschillen in gedrag. Zo onderzoeken Van der Steen et al. (2018) de vraag welke verschillende ‘waardeprofielen’ er bestaan die mede bepalen hoe rijkstrainees in de praktijk te werk gaan.Bouwsteen 2: Stellingen formuleren voor de Q-set
Naast het bepalen van de onderzoeksvraag is het belangrijk het onderwerp waarbinnen je op zoek gaat naar groepsperspectieven af te bakenen zodat het systematisch benaderd kan worden. De tweede bouwsteen bestaat daarom uit een set stellingen. Dit is het kwalitatieve deel van de methode (naast de interpretatie van de stellingen – dit volgt later). Deze stellingen zijn altijd gebaseerd op het gehele discourse, oftewel de manier waarop over het onderwerp gesproken wordt in een bepaalde, cultuur-delende groep of community (Van Exel & De Graaf, 2005; Watts & Stenner, 2012), dit wordt de concourse genoemd. Deze concourse wordt theoretisch en empirisch gereconstrueerd door de onderzoeker. De concourse-analyse wordt vervolgens omgezet in een brede set van uitspraken of statements over het onderwerp van onderzoek, waar de deelnemers zich over uit moeten spreken.
De meeste onderzoekers doen uitgebreid empirisch vooronderzoek om inzicht te krijgen in de concourse. Sommige onderzoekers gaan hierbij inductief te werk, bijvoorbeeld via interviews. Anderen gebruiken een literatuurstudie, en reconstrueren de concourse dus deductief. Van de voorbeeldstudies is voor de Evaluatie DBRA en ‘Images of Coordination’ gebruikgemaakt van interviews om de concourse inductief te reconstrueren. In de onderzoeken naar publiek-private samenwerking en rijkstrainees is de concourse opgesteld op basis van verschillende, bestaande theorieën over het onderwerp en is deze dus meer deductief. Het onderzoek naar publiek-private samenwerking gebruikte vier bestuursmodellen voor publiek-private samenwerking (namelijk: Traditional Public Administration, New Public Management, Collaborative Governance en Privatized Governance) om mogelijke uitspraken te creëren. Naast literatuur en interviews kunnen ook andere bronnen gebruikt worden, zoals (beleids)documenten, nieuwsberichten en opiniestukken. De concourse uit het onderzoek naar participatieve monitoring was gebaseerd op een combinatie van literatuur, interviews en een focusgroep-bijeenkomst. Voor de meest volledige voorstudie kan een combinatie van inductieve en deductieve methoden gebruikt worden om de concourse te verzamelen.
Het aantal stellingen in de concourse is normaliter vele malen groter dan het aantal stellingen dat voorgelegd kan worden aan de deelnemers. Zo werden in het onderzoek naar participatieve monitoring 229 verschillende uitspraken gevonden en leverde het vooronderzoek van ‘Images of Coordination’ maar liefst 615 interviewcitaten op. Uiteindelijk bestond de Q-set in deze onderzoeken uit respectievelijk 45 en 46 stellingen. Het terugbrengen van het aantal stellingen vraagt inzicht van de onderzoeker in de concourse. Bij het onderzoek naar participatieve monitoring was er sprake van een groot aantal overlappende uitspraken, die samengevoegd konden worden tot een uiteindelijke set met 46 stellingen. De set stellingen in de concourse moet worden teruggebracht, maar wel zodanig dat alle standpunten of theoretische vertrekpunten zijn vertegenwoordigd.
De uiteindelijke set stellingen (Q-set) mag niet te groot, maar ook niet te klein zijn. Er is geen harde onder- of bovengrens, maar er bestaan wel richtlijnen. Volgens Watts en Stenner (2012) zijn sets tussen de 20 en 60 stellingen het meest werkbaar. In figuur 1 is te zien dat het aantal stellingen in onze voorbeelden uiteenloopt van 25 tot en met 46. Als de Q-set groter wordt, zijn er zoveel stellingen dat de samenhang tussen de stellingen te klein wordt en er geen gezamenlijke perspectieven uit te destilleren zijn. Bovendien is het praktisch onuitvoerbaar voor de deelnemers om meer dan 60 stellingen te sorteren. Bij een te kleine set zijn er te weinig mogelijkheden om de stellingen neer te leggen, waardoor de verschillende perspectieven moeilijker te onderscheiden zullen zijn.
Hoe kies je vervolgens stellingen en hoe bepaal je of deze representatief zijn voor het gesprek over dit onderwerp? Bestuurskundige theorie kan worden gebruikt om het aantal stellingen in de concourse terug te brengen op een dusdanige manier dat alle standpunten of theoretische vertrekpunten vertegenwoordigd zijn. In ‘Images of Coordination’ is bijvoorbeeld gebruikgemaakt van een selectiematrix met twee criteria. Uit eerder onderzoek zijn negen belangrijke thema’s bekend, die spanningsvelden veroorzaken tijdens de uitvoering van horizontale beleidsprogramma’s. Het eerste criterium bestaat daarom uit deze negen mogelijke spanningsvelden, zodat deze allemaal vertegenwoordigd worden in de set met stellingen. Het tweede criterium werd gevormd door een typologie van drie soorten argumenten die mensen gebruiken (te weten: ‘dit is een feit’, ‘dit vind ik’, en ‘dit moet veranderen’). Door deze twee criteria te combineren ontstond een matrix met 27 (negen bij drie) vakken (zie tabel 2), waarbij in elke cel een of twee stellingen zijn geformuleerd op basis van de concourse. Zo bleven in deze studie 45 stellingen over. Bijvoorbeeld, in cel 5a staan stellingen over spanningsveld 5 op basis van feitelijke argumentatie, terwijl de stellingen in cel 5c over hetzelfde spanningsveld gaan, maar gericht zijn op verandering. Op deze manier helpen criteria om het aantal stellingen te reduceren en tegelijkertijd de breedte van de concourse te behouden.Tabel 2 Voorbeeld van een selectiematrix, zoals gebruikt in het onderzoek naar horizontale beleidsprogramma’sArgumentatie – typologie Mogelijke spanningsvelden 1 2 3 4 5 6 7 8 9 (a) Feiten 1a 2a 3a 4a 5a 6a 7a 8a 9a (b) Evaluatie 1b 2b 3b 4b 5b 6b 7b 8b 9b (c) Verandering 1c 2c 3c 4c 5c 6c 7c 8c 9c Bovenstaande voorbeelden laten zien dat er meerdere werkwijzen mogelijk zijn voor het samenstellen van de Q-set. Er zijn wel twee belangrijke aandachtspunten (Watts & Stenner, 2012). Ten eerste moeten alle stellingen in de set over hetzelfde onderwerp gaan en, belangrijker nog, dezelfde vraag kunnen beantwoorden. Dit in tegenstelling tot kwantitatieve modelstudies, waarbij juist meerdere onderwerpen bevraagd worden om relaties daartussen te kunnen leggen. Zo vraagt het evaluatieonderzoek naar de DBRA bijvoorbeeld hoe (niet-overheid) stakeholders de sturing van klimaatadaptatiebeleid ervaren. Als er stellingen tussen zitten die over een ander onderwerp of vraag gaan in plaats van sturing van klimaatadaptatie (bijvoorbeeld de sturing van het jeugdzorgbeleid), dan is de plaatsing van deze stellingen ten opzichte van de andere stellingen nietszeggend geworden. Men gaat dan appels met peren vergelijken. Ten tweede is het belangrijk dat elke stelling slechts op één manier geïnterpreteerd kan worden. Als er stellingen zijn die bestaan uit twee delen (‘A is beter dan B, omdat …’) en deelnemers het daarmee oneens zijn, dan is immers niet meteen duidelijk waarover zij het oneens zijn. Ze kunnen het oneens zijn met het eerste deel (‘A is beter dan B’) of met het tweede deel (ze vinden A wel degelijk beter dan B, maar om een andere dan de in de stelling gegeven reden). Dergelijke dubbelzinnigheid bemoeilijkt de interpretatie van de gevonden perspectieven. Een goede Q-set bestaat dus uit een beperkt (20-60) aantal ondubbelzinnige stellingen over een enkel onderwerp.
Bouwsteen 3: Deelnemers selecteren voor de P-set
Nadat de stellingen zijn gekozen, is het belangrijk om zorgvuldig de deelnemers voor de sortering van de Q-set te selecteren. De definitieve selectie van deze personen wordt de P-set genoemd. Omdat Q-methodologie uitgaat van subjectiviteit in plaats van personen als eenheid van analyse, worden deelnemers niet geselecteerd door middel van een representatieve steekproef uit de populatie, zoals bij kwantitatieve studies (Molenveld, 2017). Deelnemers moeten wel betekenisvol (in het Engels: purposeful) worden gekozen, dat wil zeggen dat ze theoretisch en empirisch relevant zijn voor het onderzoeksprobleem (Brown, 1980). Zo wilde men in ‘Images of Coordination’ bepalen welke beelden er bestaan bij de huidige en gewenste aanpak in horizontale beleidsprogramma’s. De deelnemers van deze studie zijn daarom mensen die verantwoordelijk zijn voor de uitvoering of integratie van drie zeer uiteenlopende horizontale beleidsprogramma’s. Daarnaast geeft Q-methodologie al vanaf dertig deelnemers goede resultaten. Door deze twee unieke kenmerken (kleine én niet-representatief sample) is het belangrijker om een P-set te selecteren die divers genoeg is om alle mogelijke perspectieven te huisvesten.
Selectie van de P-set gebeurt vaak middels selectiecriteria waarbij een of meerdere relevante empirische variabelen worden gebruikt (Molenveld, 2017). Daarbij houdt men wel in de gaten dat de groep deelnemers voldoende homogeen is om als een groep beschouwd te worden (Brown, 1980; Watts & Stenner, 2012). Zo wordt in het onderzoek naar participatieve monitoring gekozen voor waterschappen als subset van de overheidslagen. Variatie werd vervolgens bereikt doordat deelnemers met verschillende functieprofielen geworven werden bij waterschappen met verschillende opgaven en kenmerken.
Selectiecriteria in de P-set kunnen zowel op organisatieniveau als op individueel niveau worden opgesteld. ‘Images of Coordination’ maakte gebruik van criteria op organisatieniveau. Eerst werden drie verschillende horizontale beleidsprogramma’s gekozen, waarbinnen vervolgens tien organisaties met een verschillende mate van autonomie werden geselecteerd. Volgens de auteurs heeft de mate van autonomie namelijk invloed op de bewegingsruimte van organisaties en daarmee hun waardering van horizontale beleidsprogramma’s. In het onderzoek naar participatieve monitoring werden zowel criteria op het niveau van de organisatie als het individu gebruikt. Eerst werden acht van de 24 Nederlandse waterschappen geselecteerd door te variëren in de mate van verstedelijking en overstromingsgevoeligheid in het beheersgebied en de ouderdom van waterschappen. Vervolgens werd op individueel niveau gezocht naar een diversiteit door middel van functieprofielen: onder de 33 deelnemers waren zowel mensen uit de buitendienst als beleidsadviseurs. In het onderzoek naar publiek-private samenwerking is tot slot gebruikgemaakt van variatie in nationaliteit en organisatietype. Organisatiecultuur was een belangrijk theoretisch criterium. Daarom zijn zowel overheden als bedrijven betrokken en is rekening gehouden met de nationale cultuur door professionals uit drie verschillende landen mee te nemen. Naast theoretische selectiemiddelen is snowball-sampling een pragmatische manier om te zorgen dat alle standpunten vertegenwoordigd zijn. Hierbij vraagt men aan elke deelnemer om na afloop twee mensen aan te bevelen: een persoon van wie zij verwachten dat die een vergelijkbare mening heeft als zijzelf en iemand waarbij ze juist een tegenovergestelde mening verwachten. Deze eerste persoon draagt bij aan het aanscherpen van het perspectief waar zij beiden onder vallen, omdat een groter aantal mensen met hetzelfde perspectief tot een robuuster beeld van dit perspectief leidt1x De uiteindelijke viewpoints zijn gebaseerd op de gewogen gemiddeldes van de plaatsing van een stelling door deelnemers met hetzelfde perspectief. Als er maar weinig mensen op een factor laden, bestaat het risico dat individuele afwijkingen van het ‘groepsperspectief’ te zwaar meegewogen worden. Meerdere mensen die binnen hetzelfde perspectief vallen, geven dus een robuuster beeld van dit perspectief. , terwijl de tweede persoon mogelijk nieuwe perspectieven inbrengt. In het onderzoek naar participatieve monitoring zijn op deze manier vijf deelnemers geworven met een ‘afwijkende’ mening. Drie van hen bleken inderdaad in andere perspectieven te vallen dan de deelnemers die hen hadden aanbevolen. De voorbeelden hebben gemeen dat er telkens gestreefd is naar maximale variatie in subjectiviteit binnen de P-set.Bouwsteen 4: Dataverzameling door middel van sorteren
De stellingen (Q-set) en deelnemers (P-set) zelf zijn niet de data die geanalyseerd worden. De daadwerkelijke dataverzameling vindt plaats door de deelnemers de stellingen te laten sorteren. Tijdens dit proces worden de stellingen over een aantal kolommen verspreidt in een normale verdeling van ‘meest eens’ naar ‘meest oneens’ of ‘helemaal zoals ik het zie’ tot ‘helemaal niet zoals ik het zie’ of twee andere uitersten (Van Exel & De Graaf, 2005). Het aantal kolommen kan variëren (zie figuur 1), waarbij het aantal kolommen toeneemt met het aantal stellingen (zie ook Brown, 1980: 200). Andere methodologische keuzes hebben te maken met de verdeling van de stellingen over deze kolommen.
Naast het bepalen van het aantal kolommen is er de keuze tussen een open of vaste verdeling van de stellingen (Watts & Stenner, 2012). Bij een open verdeling is alleen het aantal kolommen gespecificeerd, maar staat het deelnemers vrij om zelf het aantal stellingen per kolom te bepalen. Een open verdeling biedt uitkomst als deelnemers zich te zeer beperkt voelen in het uiten van hun standpunt door een vast aantal stellingen per kolom. In theorie kan dit resulteren in een verdeling waarbij alleen de twee uiterste kolommen gebruikt worden, waarbij een meerderheid van de stellingen aan één zijde komt te liggen of waarbij elke kolom ongeveer evenveel stellingen krijgt (zie bijv. Brown, 1980: 288). Als deelnemers dit contentieus doen, maakt het voor de onderzoeksuitkomsten geen verschil, aangezien uit onderzoek blijkt dat mensen stellingen volgens een bepaalde, zij het onbewuste, systematiek neerleggen, dus ook zonder een opgelegd aantal stellingen per kolom. Brown (1980) beschrijft echter wel het risico dat mensen zich (al dan niet met opzet) niet meer duidelijk uitspreken als ze de kans krijgen voor een open distributie. Alle gebruikte voorbeeldstudies en veruit de meeste Q-studies maken daarom gebruik van een vaste verdeling.
De verdeling van de stellingen over de kolommen krijgt typisch de vorm van een normale verdeling, met weinig stellingen in de extremen van meest eens en meest oneens en meer stellingen richting het min of meer neutrale midden (Brown, 1980). Wat opvalt, is dat sommige studies eenzelfde aantal kolommen gebruiken, maar dat het exacte aantal stellingen per kolom kan verschillen. Dit komt omdat de onderzoeker kan spelen met de steilheid van de normale verdeling. Welke verdeling exact gekozen wordt, maakt voor de statistische analyse niet uit (Brown, 1980: 288), al raden Watts en Stenner (2012) wel aan een steilere verdeling te kiezen als de deelnemers heel veel weten van het onderwerp, en dus goed weten welke stellingen zij aan de uiteinden willen leggen (zoals de meest rechter verdelingen in figuur 1). Een plattere verdeling en/of een groter neutraal midden kan worden gekozen als de deelnemers minder uitgesproken zijn, bijvoorbeeld doordat zij weinig ervaring met het onderwerp hebben. (Brown, 1980; Van Exel & De Graaf, 2005). Er is bovendien geen vuistregel voor het aantal stellingen op de extremen, maar een zo klein mogelijk aantal geeft de beste resultaten (Watts & Stenner, 2012). Dit komt doordat Q-methodologie uitgaat van zogenaamde parabolische significantie, of in andere woorden: de buitenste kolommen worden als het meest saillant en daarmee significant gezien, terwijl stellingen in het ‘neutrale midden’ als betekenisloos worden beschouwd (Brown, 1980). De meeste onderzoekers kiezen daarom voor een vorm vergelijkbaar met die uit de voorbeeldstudies.Figuur 1 Overzicht gebruikte verdelingen; het vijfde voorbeeld (gedragsprofielen rijkstrainees) heeft niet gemeld hoeveel stellingen er per kolom geplaatst moesten worden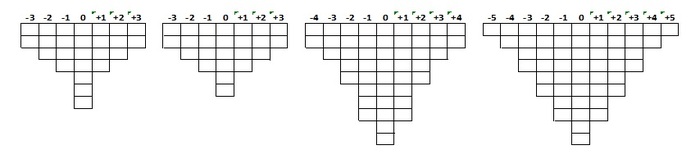 V.l.n.r.: Tussenevaluatie DBRA; Publiek-private samenwerking; Participatieve monitoring; ‘Images of Coordination’
V.l.n.r.: Tussenevaluatie DBRA; Publiek-private samenwerking; Participatieve monitoring; ‘Images of Coordination’ Het proces van sorteren kan in persoon (zie figuur 2) of online worden georganiseerd. De voor- en nadelen van online en in persoon sorteren zijn samengevat in tabel 3. Het online sorteren biedt voordelen voor zowel de deelnemer als onderzoeker. De deelnemer kan de sortering doen op een moment dat hem/haar uitkomt en kan bovendien anoniem aan het onderzoek deelnemen. Voor de onderzoeker levert online sorteren bovendien flinke tijdswinst op. Online sorteringen bieden bovendien kansen voor een grotere of geografisch verspreide P-set, zoals in het onderzoek naar publiek-private samenwerking met deelnemers uit drie landen. De onderzoekers konden zo met relatief weinig middelen drie Q-studies in de drie onderzoekslanden doen. Online sorteren biedt ook de mogelijkheid om geen P-set te selecteren, maar de hele populatie uit te nodigen. Een dergelijke open uitnodiging loopt wel het risico van zelfselectie, waarbij alleen een bepaald type uit de populatie zichzelf aanmeldt en de P-set dus onvoldoende subjectieve diversiteit bevat. Een praktische maar methodologisch gezien minder elegante oplossing voor dit probleem is om zoveel mogelijk mensen te laten deelnemen, zoals Van der Steen et al. (2018) gedaan hebben door maar liefst 116 rijkstrainees te laten sorteren.
Figuur 2 In persoon sorteren: de deelnemer legt kaartjes met de stellingen neer volgens een vast patroon op bijvoorbeeld een tafel
Een belangrijk nadeel van in persoon sorteren is dat het veel onderzoekstijd kost, in het onderzoek naar participatieve monitoring 60-75 minuten per deelnemer. Tegelijkertijd biedt het een belangrijk voordeel, namelijk de mogelijkheid om een post-sort interview te houden waarin deelnemers uitgebreid hun sortering toelichten (Gallagher & Porock, 2010). Deze post-sort interviews zijn een waardevolle toevoeging bij het interpreteren van de verschillende perspectieven in de latere fasen van het onderzoek en worden ten onrechte vaak weggelaten (Brown, 1980). Het komt ook tegemoet aan de kritiek die er weleens is op Q-methodologie, dat het maar een beschrijvende methode is en geen uitspraak kan doen over het waarom (Brown, 1980). Door middel van quotes en meer onderbouwing kan de onderzoeker meer diepgaand laten zien hoe een bepaalde denkwijze tot stand komt.
Tabel 3 Voor- en nadelen van online en in persoon sorterenOnline In persoon Tijdsefficiënt voor onderzoeker Tijdsintensief voor zowel onderzoeker als deelnemer Instructie is kort en bondig, geen mogelijkheid voor extra uitleg of vragen stellen Mogelijkheid om de deelnemer van extra uitleg te voorzien en te zorgen dat hij/zij de procedure helemaal begrijpt Deelnemer kan korte toelichting op enkele stellingen achterlaten, meestal de extremen Deelnemer kan actief bevraagd worden over enkele tot alle stellingen in een post-sort interview Reactie en feedback van de deelnemer op de stellingen bereikt de onderzoeker niet De onderzoeker kan de reactie van de deelnemers (zoals non-verbale reacties en opmerkingen over onduidelijke stellingen) meenemen in het onderzoek Deelnemer kan anoniem blijven Deelnemer voelt mogelijk druk om stellingen sociaal-wenselijk neer te leggen Bouwsteen 5: Data-analyse met behulp van factoranalyse
Nadat de gegevens zijn verzameld – in de vorm van alle verschillende Q-set sorteringen (ook wel Q-sorts genoemd) van de deelnemers – is het tijd om het analyseproces te starten. Er zijn verschillende softwarepakketten om onderzoekers bij dit proces te helpen, maar de analyse – zo waarschuwen de experts – mag niet ‘mechanisch’ worden uitgevoerd. Hieronder bespreken wij daarom de drie stappen van de data-analyse: correlaties tussen de Q-sorts bepalen, een factoranalyse en het berekenen van ‘factor scores’ (Mckeown & Thomas, 2011).
Een eerste stap in de analyse is het berekenen van de correlatie tussen de verschillende Q-sorts, met andere woorden: bepalen in hoeverre twee Q-sorts aan elkaar verwant zijn. Deze correlaties worden in een matrix opgeslagen, waarbij de matrix evenveel rijen en kolommen heeft als er Q-sorts zijn (Brown, 1980). Het onderzoek naar rijkstrainees met 116 deelnemers (en dus evenveel Q-sorts) kreeg dus een matrix van 116 x 116 cellen.
Vervolgens wordt door middel van een factoranalyse bepaald hoeveel significant verschillende clusters er bestaan in deze dataset van correlaties. Elke factor representeert hierbij een dergelijk cluster. Aangezien de factoranalyse zelf slechts een wiskundige handeling is, kunnen er in theorie oneindig veel factoren gevonden worden. De uitdaging is dus om het juiste aantal factoren te bepalen. Watts en Stenner (2012) hebben een aantal richtlijnen voorgesteld voor onderzoekers die proberen te bepalen hoeveel factoren zij uit hun gegevens willen halen. Een goed startpunt om te bepalen hoeveel factoren (en dus gedeelde gezichtspunten) je uit de gegevens kunt extraheren, is gebaseerd op een ondergrens van 1 voor de Eigenwaarden (Engels: Eigenvalues) van een factor (Watts & Stenner, 2012). Daarnaast hebben Webler et al. (2001) gebruikgemaakt van vier criteria om te bepalen hoeveel factoren moeten worden gerapporteerd:Elke factor moet een verklarende waarde hebben die groter is dan 3%.
Ten minste twee deelnemers moeten significant op de factor laden.
De factor moet van theoretisch belang zijn en de bevindingen moeten logisch zijn.
De correlatie tussen de factoren moet kleiner zijn dan 0,33, wat betekent dat de factoren onderscheidend zijn.
Door deze richtlijnen te volgen kunnen auteurs ervoor zorgen dat ze alleen factoren vermelden die relevant zijn voor het bestudeerde onderwerp. Er wordt bewust gekozen voor het woord ‘richtlijn’, aangezien onderzoekers hier beredeneerd van af kunnen wijken. Zo had de derde factor in participatieve monitoring een eigenwaarde van 0,96 (oftewel: kleiner dan 1). Desondanks is deze factor meegenomen, omdat deze theoretisch van belang was en bij de kwalitatieve interpretatie zich wel degelijk bleek te onderscheiden van de andere factoren. Naast deze vuistregels zijn er nog vele andere, waaronder de hellingtest (Engels: scree test), parallelle analyse van Horn en de regel van Humphrey. Watts en Stenner (2012) sommen het geheel op in hun boek, maar voor een eerste kennismaking met Q-methodologie volstaan bovenstaande richtlijnen. Softwarepakketten bieden bovendien een automatische (en daarmee puur numerieke) selectie van een geschikt aantal factoren. Bovenstaande richtlijnen worden toegepast op de factoren die ontstaan uit de factoranalyse.
Na deze factoranalyse dienen deze ‘ruwe factoren’ echter in twee stappen te worden bewerkt tot een factor-reeks die klaar is voor interpretatie. Ten eerste worden de ruwe factoren gedraaid. Het is onmogelijk om in deze korte bijdrage het hoe en waarom van deze handeling volledig toe te lichten. Kort gezegd worden de Q-sorts geplot als coördinaten in een assenstelsel van twee factoren, waarna de assen gedraaid worden. Het doel is om de assen zo te draaien dat de coördinaten (factor loadings) zoveel mogelijk langs de assen komen te liggen, zodat de onderzoeker deze het gemakkelijkst en meest betekenisvol kan interpreteren (Mckeown & Thomas, 2011). Watts en Stenner (2012, p. 113-143) geven een uitgebreide handleiding voor handmatige rotatie en selectie, maar softwareprogramma’s als PQMethod en KenQ bieden de optie van geautomatiseerd draaien en selecteren. Hoewel deze door zowel onervaren als ervaren gebruikers van Q-methodologie gebruikt worden, maakt deze gebruik van wiskundige criteria. Een handmatige, theoretisch gedreven rotatie is daarom een waardevolle aanvulling (Brown, 1980; Mckeown & Thomas, 2011). Ten tweede wordt een gewogen gemiddelde gemaakt van alle sorteringen van de deelnemers (Q-sorts) die bijdragen aan een factor, die in andere woorden gelijkaardig zijn. Elke Q-sort heeft een bepaalde loading op elke factor, dat wil zeggen een getal tussen 0 en 1 die aangeeft in hoeverre zijn/haar individuele perspectief overeenkomt met deze factor. Ter illustratie: deelnemer 23 in het onderzoek naar participatieve monitoring had een loading van 0,82 op factor 1, 0,17 op factor 2 en 0,04 op factor 3. Deze Q-sort is dus betekenisvol voor de eerste, maar niet voor de tweede en derde factor. Er zijn enkele richtlijnen voor het selecteren van ‘betekenisvolle’ Q-sorts, zoals een bepaalde drempelwaarde (bijvoorbeeld 0,5) of de eis dat een Q-sort niet in meerdere factoren een hoge loading mag hebben om het gewogen gemiddelde en daarmee de perspectieven zo ‘puur’ mogelijk te houden (Brown, 1980; Watts & Stenner, 2012). Het uitvoeren van beide bewerkingen kan automatisch worden gedaan op basis van wiskundige regels, terwijl een handmatige bewerking ook theoretische afwegingen meeneemt. Dit vergt echter oefening en fingerspitzengefühl van de onderzoekers.
Nadat de onderzoeker het aantal factoren heeft bepaald, is het tijd voor de interpretatie van de resultaten. Daarvoor is het waardevol om kwalitatieve informatie mee te nemen. Onderzoekers kunnen de analyse verrijken met citaten van deelnemers die significant op een factor laden om betekenis toe te kennen aan de analyseresultaten en de interpretatie van de onderzoeker te verduidelijken (Van Exel & De Graaf, 2005). Met deze stap kunnen onderzoekers de lezer laten zien en voelen hoe de wereld eruitziet vanuit het perspectief van de deelnemers. Daarom vertrouwen de meeste Q-onderzoeker op kwalitatieve gegevens om de kwantitatieve gegevens te verifiëren. Naast het opnemen van interviewcitaten is het aan te bevelen om rekening te houden met karakteriserende, onderscheidende en consensus-stellingen bij het schrijven en positioneren van de verhalen. Karakteriserende stellingen zijn die uitspraken die het hoogst of het laagst zijn gerangschikt binnen een factor. Onderscheidende uitspraken zijn die met een score die statistisch significant verschilt van hun score in alle andere factoren. Consensus-stellingen zijn die stellingen waarvoor scores niet statistisch verschillend waren tussen een paar factoren, in andere woorden: waar deelnemers het over eens zijn (zie Watts & Stenner, 2012). De combinatie van kwalitatieve informatie en de karakteriserende, onderscheidende en consensus-stellingen per factor vormen samen een beschrijving van het standpunt behorende bij deze factor, de zogeheten narrative. Deze narratives zijn de verschillende perspectieven die bestaan binnen de groep en vormen daarmee een antwoord op de onderzoeksvraag uit bouwsteen 1. -
3 Zelf aan de slag – in tien stappen
Hierboven zijn de theoretische en analytische bouwstenen geïntroduceerd en toegelicht. Deze bouwstenen laten de belangrijkste onderliggende methodologische filosofie en concepten zien. In deze laatste paragraaf presenteren we een praktisch stappenplan om zelf aan de slag te gaan met Q-methodologie, met hierin tips voor software en tools. Dit stappenplan onderscheidt zich van de bouwstenen doordat dit stappenplan gebaseerd is op de ervaringen met de methode van de twee auteurs van deze bijdrage en ook praktische tips bevat. In beginsel heb je weinig nodig: een set stellingen, deelnemers en software voor de data-analyse, zoals ook beschreven in de bouwstenen. In Q-literatuur wordt het proces opgedeeld in een wisselend aantal stappen, wij onderscheiden er tien.
Stap 1. Verken het thema. Voordat je een studie uitzet, is het altijd belangrijk om het issue te verkennen waar je onderzoek naar doet. Omdat je met Q-methodologie specifiek op zoek gaat naar significant verschillende zienswijzen in een bepaald debat is het belangrijk te weten wat het debat precies is, waar het over gaat, wie belangrijke spelers zijn en waar deze spelers eventueel staan in het debat. Dit kan door middel van een documentenstudie (beleidsdocumenten, krantenartikelen e.d.), maar ook via gesprekken met sleutelactoren.
Stap 2. Neem interviews af of organiseer een focusgroep. Na een eerste verkenning van het debat kan het helpen om een aantal interviews af te nemen of een focusgroep te organiseren. In de volgende fase van het onderzoek worden er stellingen geselecteerd, die herkenbaar zouden moeten zijn voor de deelnemers aan de studie. Het in gesprek gaan met de belangrijke spelers helpt om de belangrijkste gevoeligheden te identificeren, maar ook om het specifieke ‘jargon’ van deze groep te leren kennen.
Stap 3. Selecteer statements. Uit het verkennende onderzoek destilleert de onderzoeker een aantal stellingen die hij/zij in een latere fase wil voorleggen aan de deelnemers. Deze stellingen moeten representatief zijn voor het issue dat onderzocht wordt, wat betekent dat zowel het onderwerp als de manier van formuleren zo divers mogelijk is en het hele debat over het issue gaat.
Stap 4. Ontwerp een stellingenrooster. Afhankelijk van het aantal stellingen ontwerpt de onderzoeker een normale verdeling waarin de stellingen passen, met een schaal van bijvoorbeeld -4 tot +4, zodat de deelnemers gemakkelijk de stellingen kunnen ordenen en relatief ten opzichte van elkaar kunnen plaatsen.
Stap 5. Zoek je software uit of print kaartjes. Ga je voor een Q-studie via een online tool, zoek dan in deze fase naar de software (bijv. Flash Q,2x www.hackert.biz/flashq/home/ Q sortware3x http://qsortware.net/ of qmethodsoftware4x https://app.qmethodsoftware.com/ ). Als je interviews afneemt om de sorteringen samen met de deelnemers te doen, zorg er dan voor dat je zowel het stellingenrooster als de kaartjes met stellingen print. Dit zijn makkelijke hulpmiddelen om het gesprek aan te gaan en voorkomen verwarring over het aantal stellingen per kolom.
Stap 6. Selecteer je deelnemers. In principe werkt Q-methodologie niet met een representatief sample van deelnemers, omdat de gevonden factoren achteraf niet een-op-een terugslaan op de personen die deelnamen. Wel raden wij aan om het profiel van de deelnemers duidelijk te definiëren, om er zeker van te zijn dat de deelnemers tot de doelgroep behoren en daarbinnen voldoende verschil van perspectief hebben. Ook kan het helpen om vooraf een richtgetal voor het aantal deelnemers te bepalen, bijvoorbeeld ‘30-40 deelnemers’.
Stap 7. Laat de stellingen sorteren. Tijdens interviews of online kunnen deelnemers de stellingen rangschikken; de vuistregel is dat je ongeveer aan 30 deelnemers genoeg hebt. Bij online sorteren is het belangrijk dat de instructies duidelijk zijn. Deelnemers hebben immers geen mogelijkheid tot het stellen van vragen over de procedure of centrale vraagstelling. Bij in persoon sorteren is 60-90 minuten een goede tijdsindicatie, enigszins afhankelijk van het aantal stellingen. Bij een langere tijdsduur weigeren respondenten mogelijk deelname. Ook is het niet altijd mogelijk om alle stellingen te bespreken. Vraag in het post-sort interview daarom in eerste instantie naar de stellingen op de extremen (meest en minst eens), stellingen waarin je als onderzoeker geïnteresseerd bent en stellingen waarover de deelnemer zelf iets kwijt wil. Als de tijd het toelaat, kunnen alle stellingen worden besproken.
Stap 8. Registreer de sorteringen in de analyse-software. Als alle reacties binnen zijn, kun je beginnen aan het registreren van de sorteringen in de software. Dit kan direct in het programma PQMethod,5x http://schmolck.org/qmethod/ andere programma’s vragen om een .csv file of .exl-bestand om de data te kunnen lezen, bijvoorbeeld KenQ analysis.6x https://shawnbanasick.github.io/ken-q-analysis/ Op de bijbehorende websites zijn handleidingen te vinden voor het gebruik van de software.
Stap 9. Analyseer de factoren. De data-analyse (factoren, draaien) kan worden gedaan met behulp van PQMethod of de KenQ web-based tool. De analyse levert een aantal zaken op, natuurlijk de significant verschillende factoren, maar daarnaast ook onderscheidende, karakteriserende en consensus-stellingen. Deze helpen bij de interpretatie in de volgende stap. Ook laat de software zien waar de factoren vooral verschillen en in hoeverre een individueel perspectief overeenkomt met een bepaalde factor.
Stap 10. Interpreteer de factoren. Om de factor te interpreteren bekijk je de onderscheidende, karakteristieke en consensus-statements. Je probeert een ‘narratief’ te ontwikkelen: wat vinden deze deelnemers, waar staan ze in dit debat? Om dit te begrijpen kun je teruggaan naar de interviews of de factoren proberen te linken aan bestaande concepten of literatuur. In Q-studies worden veelvuldig quotes gebruikt om een factor uit te leggen.
Naast deze en andere handleidingen, artikelen en handboeken is er een mailinglist waar experts elkaar op de hoogte houden van nieuwe Q-artikelen, -conferenties en -ontwikkelingen. Ook worden hier regelmatig vragen gesteld over de methode en leggen (beginnende) gebruikers van de methode vaak dilemma’s in de dataverzameling of -analyse voor. Aanmelden voor de mailinglist kan via https://qmethod.org/community/mailing-list/.Voor- en nadelen van de methode
In wezen is er nog een belangrijke ‘stap 0’ toe te voegen aan dit stappenplan: bedenk of de methode geschikt is voor het onderzoeksprobleem en of deze praktisch uitvoerbaar is. Zoals eerder opgemerkt is Q-methodologie geen panacee dat geschikt is voor elk probleem of voor elke onderzoeksvraag. Ook zijn er – zoals aan elke methode – voor- en nadelen aan Q-methodologie. Wij onderscheiden drie belangrijke voordelen. Een eerste voordeel is dat Q-methodologie relatief snel zicht biedt op de significante verschillen tussen denkpatronen in een bepaalde groep. Een tweede voordeel is dat Q-methodologie de voordelen van kwalitatieve (diepgang) en kwantitatieve (significante en relatief eenvoudig te presenteren resultaten) onderzoeksmethoden combineert. Een derde voordeel is dat er relatief weinig deelnemers nodig zijn voor deze methode.
Natuurlijk kleven er ook nadelen aan de methode. Allereerst heeft Q-methodologie tot doel een beschrijving te bieden en biedt het geen verklaringen. Voor een verklarend onderzoek zijn andere of aanvullende methoden nodig. Ten tweede is er een relatief grote tijdsinvestering nodig van de onderzoekers om het debat goed te doorgronden en de stellingen te selecteren. Daarnaast is er het risico op een druk-op-de-knop- of mechanisch analyseproces, waarbij de resultaten verminderd theoretisch relevant zijn. De statistische kant is mechanisch gezien gemakkelijk uit te voeren met behulp van softwarepakketten, maar om de analysemethode goed te begrijpen is tijd nodig. -
4 Tot slot: toepassingen in de praktijk
Het openbaar bestuur en de bestuurskunde houden zich bezig met het aansturen en ontrafelen van processen, standpunten van belanghebbenden en het gedrag van mensen. Dit zou kunnen verklaren waarom Q-methodologie langzaam aan terrein wint in de academische wereld (Molenveld, 2017). Q-methodologie is niet alleen een interessante methode voor beleidsonderzoekers, maar ook bedrijven of overheden kunnen Q-methodologie inzetten. Dit roept wel de vraag op hoe Q-methodologie dan in de praktijk gebruikt kan worden. We zien drie belangrijke toepassingen voor Q-methodologie op het gebied van beleid. Ten eerste kan Q-methodology gebruikt worden om de bestaande praktijk te beschrijven. Ten tweede kunnen de resultaten gebruikt worden als input voor beleidsformulering (zoals Participatieve monitoring en ‘Images of Coordination’). Men kan zich eenvoudig indenken dat het nuttig is bij het maken van een belangrijke beslissing om te weten welke perspectieven er bestaan onder burgers of andere stakeholders. Tot slot kan de methode gebruikt worden voor beleidsevaluatie (zoals bij de Tussentijdse Evaluatie Ruimtelijke Adaptatie).
De in deze bijdrage geïntroduceerde methodologie is uniek en combineert kwalitatieve en kwantitatieve elementen. Het is een van de weinige methoden die specifiek gericht is op het ontdekken van patronen van consensus en conflict en het systematisch bestuderen van subjectiviteit. In plaats van specifieke persoon- of organisatie-specifieke items te vergelijken, helpt de methode onderzoekers of beleidsmakers om verscheidenheid en meerdere naast elkaar bestaande denkpatronen vast te leggen (Durose et al., 2016). Het ontrafelen van veelvormigheid en denkpatronen is nuttig voor het informeren en evalueren van beleid, en voor het generaliseren van concepten. Zo kan Q-methodologie bijvoorbeeld gebruikt worden als verkennende methode om beleidspraktijken te informeren en te evalueren. Anderzijds kan het een methode zijn om ex ante visies op een bepaald onderwerp te bestuderen voor de beleidsontwikkeling of voor een nieuwe vorm van sturing. Literatuur Brown, S.R. (1980). Political subjectivity: Applications of Q methodology in political science. New Haven, CT: Yale University Press.
Brown, S.R. (1993). A primer on Q methodology. Operant Subjectivity, 16(3/4), 91-138.
Brown, S.R. (1996). Q methodology and qualitative research. Qualitative Health Research, 6(4), 561-567.
De Graaff, R., Steegh, J., Aerts, M., Van der Brugge, R., Van Buuren, A., Dekker, G., … Loeber, A. (2017). Tussentijdse evaluatie ruimtelijke adaptatie, reflecteren en inspireren: Eindrapport. Leiden.
Durose, C., Van Hulst, M., Jeffares, S., Escobar, O., Agger, A., & De Graaf, L. (2016). Five ways to make a difference: Perceptions of practitioners working in urban neighborhoods. Public Administration Review, 76(4), 576-586.
Gallagher, K., & Porock, D. (2010). The use of interviews in Q methodology: Card content analysis. Nursing Research, 59(4), 295-300.
Head, B.W., & Alford, J. (2015). Wicked problems. Administration & Society, 47(6), 711-739.
Kampen, J.K., & Tamás, P. (2014). Overly ambitious: Contributions and current status of Q methodology. Quality and Quantity, 48(6), 3109-3126.
Mckeown, B.B., & Thomas, D. (2011). Q methodology. Thousand Oaks, CA: SAGE Publications.
Minkman, E., Van Der Sanden, M., & Rutten, M. (2017). Practitioners’ viewpoints on citizen science in water management: A case study in Dutch regional water resource management. Hydrology and Earth System Sciences, 21(1), 153-167.
Molenveld, A. (2017). Using Q methodology for (comparative) policy analysis. In 3rd International Conference on Public Policy (pp. 1-15). Singapore: International Public Policy Association.
Molenveld, A., & Nederhand, J. (under review). Q-Methodology: state of the art in Public Administration research. In B.G. Peters & I. Thynne (Eds.), Encyclopedia of Public Administration. Oxford University Press.
Molenveld, A., Verhoest, K., Voets, J., & Steen, T. (2020). Images of coordination: How implementing organizations perceive coordination arrangements. Public Administration Review, 80(1), 9-22.
Sell, D.K., & Brown, S.R. (1984). Q methodology as a bridge between qualitative and quantitative research: Application to the analysis of attitude change in foreign study program participants. Qualitative Research in Education, 79, 87.
Stephenson, W. (1935). Technique of factor analysis. Nature, 136(3434), 297.
Teisman, G., Gerrits, L., & Van Buuren, A. (2009). Managing complex governance systems: Dynamics, self-organization and coevolution in public investments. New York: Routledge.
Van der Steen, M., Van Twist, M.J.W., & Bressers, D. (2018). The sedimentation of public values: How a variety of governance perspectives guide the practical actions of civil servants. Review of Public Personnel Administration, 38(4), 387-414.
Van Exel, J., & De Graaf, G. (2005). Q methodology: A sneak preview. Social Sciences, 2, 1-30.
Warsen, R., Greve, C., Klijn, E.H., Koppenjan, J.F.M., & Siemiatycki, M. (2019). How do professionals perceive the governance of public-private partnerships? Evidence from Canada, the Netherlands and Denmark. Public Administration, (August), 1-16.
Watts, S., & Stenner, P. (2012). Doing Q methodological research: theory, method and interpretation. London: SAGE Publications.
Webler, T., Tuler, S., & Krueger, R. (2001). What is a good public participation process? Five perspectives from the public. Environmental Management, 27(3), 435-450.
-
1 De uiteindelijke viewpoints zijn gebaseerd op de gewogen gemiddeldes van de plaatsing van een stelling door deelnemers met hetzelfde perspectief. Als er maar weinig mensen op een factor laden, bestaat het risico dat individuele afwijkingen van het ‘groepsperspectief’ te zwaar meegewogen worden. Meerdere mensen die binnen hetzelfde perspectief vallen, geven dus een robuuster beeld van dit perspectief.
Citeerwijze van dit artikel:
Ellen Minkman en Astrid Molenveld, ‘Q-methodologie als methode om beleid te beschrijven, te ontwikkelen of te evalueren’, 2020, januari-maart, DOI: 10.5553/BO/221335502020000001001
Beleidsonderzoek Online |
|
| Artikel | Q-methodologie als methode om beleid te beschrijven, te ontwikkelen of te evalueren |
| Auteurs | Ellen Minkman en Astrid Molenveld |
| DOI | 10.5553/BO/221335502020000001001 |
|
Toon PDF Toon volledige grootte Samenvatting Auteursinformatie Statistiek Citeerwijze |
| Dit artikel is keer geraadpleegd. |
| Dit artikel is 0 keer gedownload. |
Ellen Minkman en Astrid Molenveld, 'Q-methodologie als methode om beleid te beschrijven, te ontwikkelen of te evalueren', Beleidsonderzoek Online januari 2020, DOI: 10.5553/BO/221335502020000001001
|
Q-methodologie is een nog relatief onbekende onderzoeksmethode, met veel potentieel voor beleidsonderzoek en -analyse. De benaderingen, doelen en onderzoeksvragen in verschillende toepassingen lopen uiteen, maar vertonen ook duidelijke overeenkomsten. In dit artikel beschrijven we de belangrijkste theoretische en analytische bouwstenen van de methode, en een praktijkgericht 10-stappenplan waarmee men snel zelf aan de slag kan met Q-methodologie. Op basis van een aantal toepassingen van Q-methodologie in Nederland en Vlaanderen laat dit artikel op inzichtelijke wijze zien wat Q-methodologie toevoegt aan de toolbox van beleidsonderzoekers. Naast de theoretische achtergrond van de methode biedt deze bijdrage een praktisch stappenplan voor het gebruik van de methode in de praktijk. |
